How HashMap works internally
As we know, hashmap is a data structure that contains key/value pair. But how a hash map works internally, we will understand this here.
Before proceeding, we should understand equals() and hashCode() contract. To understand it, click here.
How hashmap works?
The first point to understand is how entries of key/value pair are stored in hash map. It uses a technique called hashing to store entries. One entry is represented as a node object.
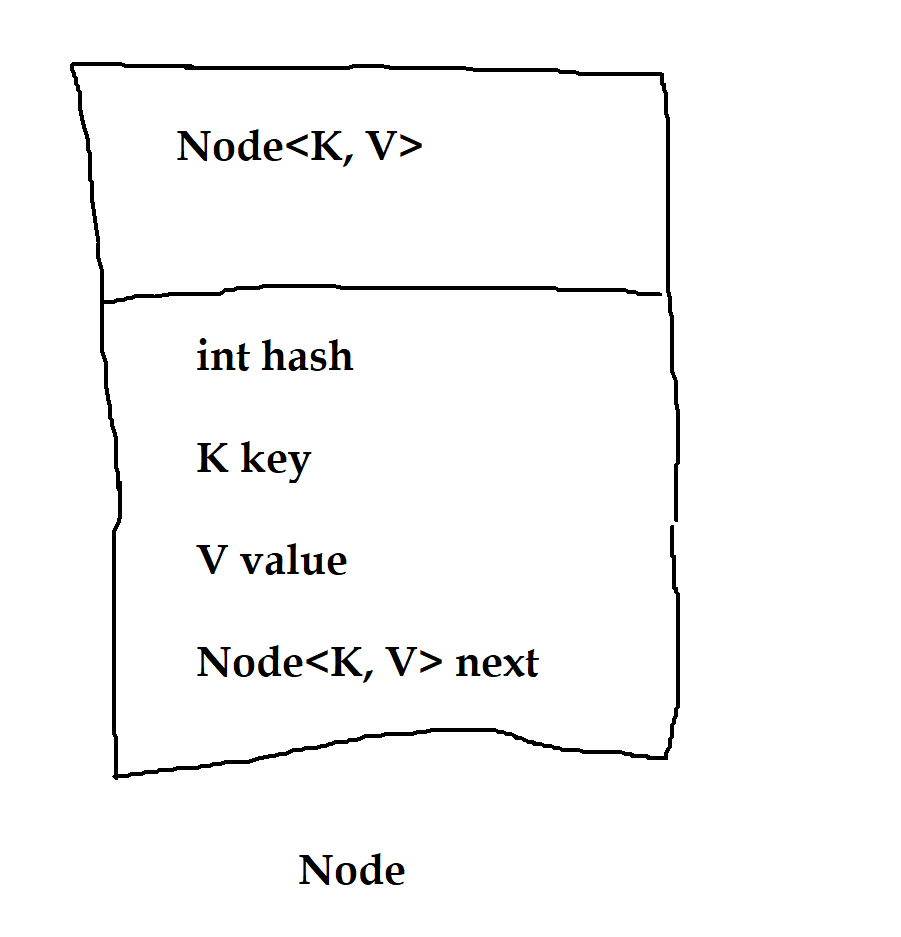
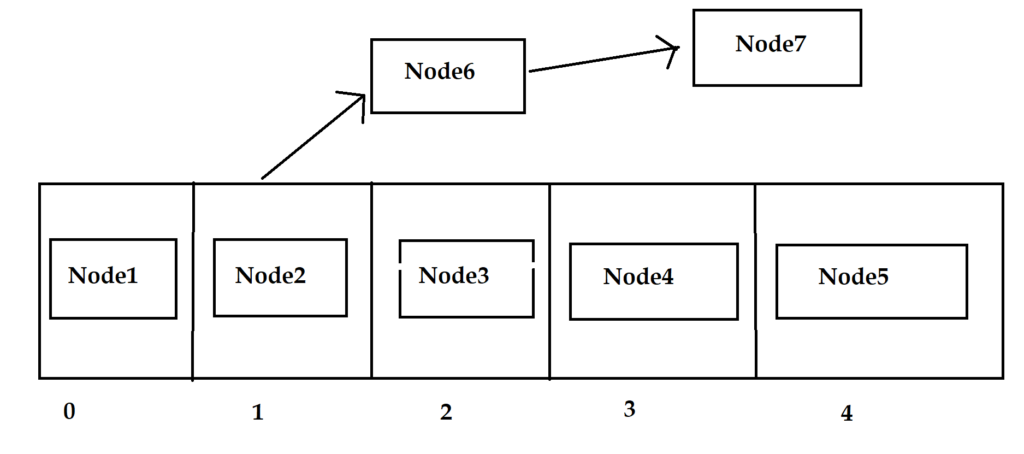
Hash map stores these nodes in the form of an array. Also, it is possible that more than one node can have the same index. In that case, nodes form a linked list. It is explained in the below diagram.
What is bucket location
You would be hearing this term ‘bucket’ very frequently while understanding the internal working of a hashmap, and thus it is important to understand what is a bucket location.
We learnt that nodes are stored in an array. Each array location (index) is called bucket location.
How put() method in hashmap works
The following things happen when an entry needs to be added in hashmap.
- First of all, it is checked if the key to be stored is null or not. If null, then value against this null key is stored at table[0] bucket location. Because hashcode for null key is 0, therefore bucket location is table[0].
- Secondly, when key is not null, hash code of the key is calculated using hashCode() method.
- Since hashCode() implementation is left to the developers. There are good chances that it might be a poorly written hashCode(), which might not give expected bucket location. To overcome this issue, one more step is followed. It is explained in the next step.
- The hash code value obtained using hashCode() method is passed to another hash() function to calculate the index of the bucket. Its implementation is such that resultant hash value comes in the range of array index size. Finally, indexFor() method exactly gives the index position.
- HashMap uses multiple buckets and each bucket points to a Singly Linked List where the entries (nodes) are stored.
- Once the bucket is identified by the hash function using hashcode, then hashCode is used to check if there is already a key with the same hashCode or not in the bucket.
- If there already exists a key with the same hashCode, then the equals() method is used on the keys. If the equals method returns true, that means there is already a node with the same key and hence the value against that key is overwritten in the entry(node), otherwise, a new node is created and added to this Singly Linked List of that bucket.
How collisions are resolved
More than one object can have same hash code value, and they can be unequal too. In such situations, collision occur since two unequal objects have same bucket location. How it is resolved?
It is resolved using LinkedList. Whenever such collisions occur, entries are stored in the form of LinkedList.
How get() method works in hash map
- Uniqueness of the key is determined exacly the same way as it is done in put() method.
- As the exact match of the key is found, it returns the value object against this key stored in current entry object.
- If key is not found, it return null.
Time Complexity
- In a fairly distributed hashMap where the entries go to all the buckets in such a scenario, the hashMap has O(1) time for search, insertion, and deletion operations.
- In the worst case, where all the entries go to the same bucket and the singly linked list stores these entries, O (n) time is required for operations like search, insert, and delete.
- In a case where the threshold for converting this linked list to a self-balancing binary search tree(i.e. AVL/Red black) is used then for the operations, search, insert and delete O(logN) is required as AVL/Red Black tree has a max length of logN in the worst case.
This article is written by Unmesh Joshi. He is a US based Software Engineer.
